Инструменты распознавания лиц - это вычислительные модели, которые могут идентифицировать конкретных людей на изображениях, а также на записях камер видеонаблюдения или видеозаписей. Эти инструменты уже используются в широком спектре реальных ситуаций, например, помогая сотрудникам правоохранительных органов и пограничного контроля в их уголовных расследованиях и усилиях по наблюдению, а также для аутентификации и биометрических приложений. Хотя большинство существующих моделей работают на удивление хорошо, все еще может быть много возможностей для улучшения. Исследователи из Лондонского университета королевы Марии недавно создали новую и многообещающую архитектуру для распознавания лиц. Эта архитектура, представленная в статье, предварительно опубликованной на arXiv, основана на стратегии извлечения черт лица из изображений, которая отличается от большинства предложенных до сих пор.
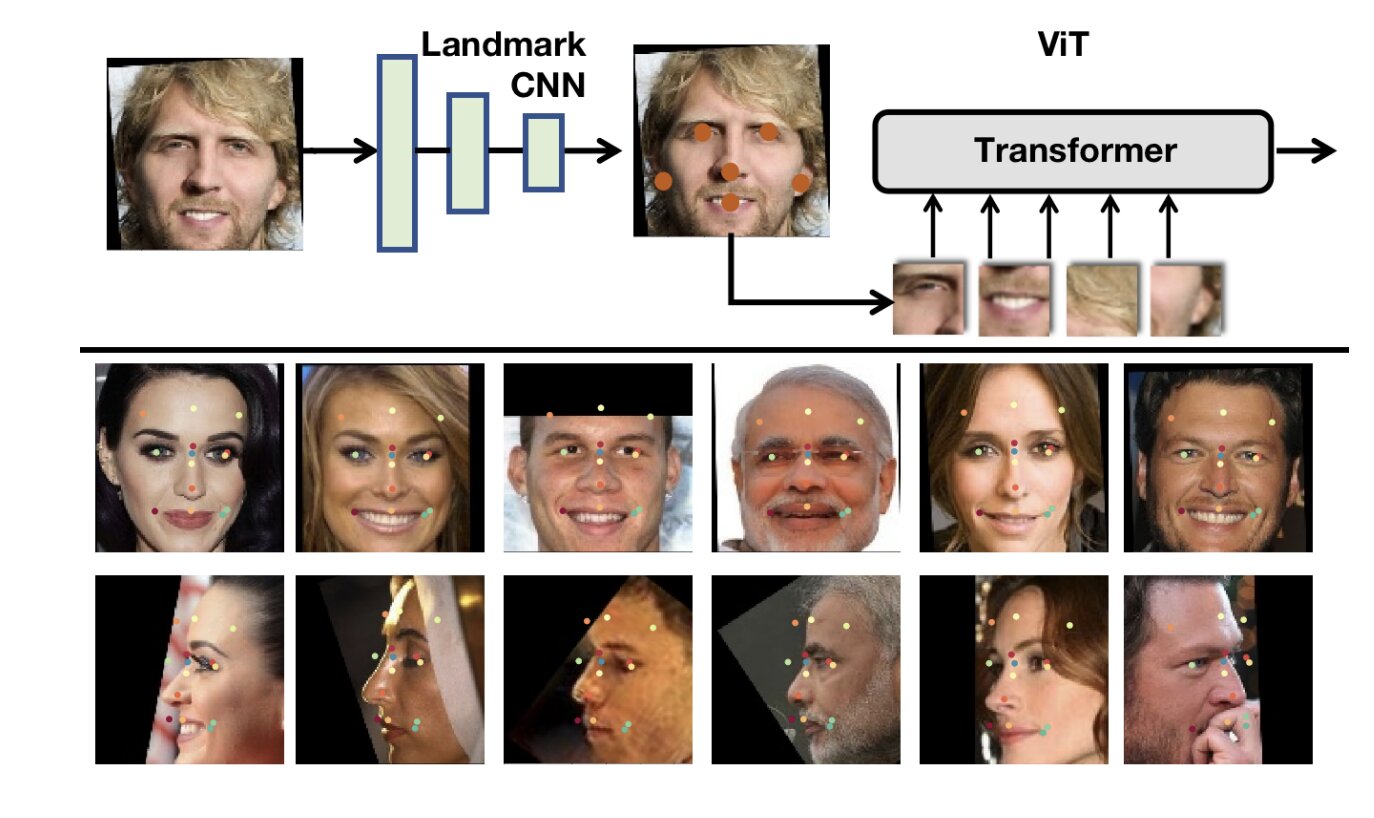
"Целостные методы, использующие сверточные нейронные сети (CNN) и потери на основе маржи, доминировали в исследованиях по распознаванию лиц", - рассказали TechXplore Чжунлин Сан и Георгиос Цимиропулос, два исследователя, которые проводили исследование. "В этой работе мы отходим от этой установки двумя способами: (а) мы используем Vision Transformer в качестве архитектуры для обучения очень сильной базовой линии для распознавания лиц, просто называемой fViT, которая уже превосходит большинство современных методов распознавания лиц. (б) Во-вторых, мы извлекаем выгоду из присущего преобразователю свойства обрабатывать информацию (визуальные маркеры), извлеченную из нерегулярных сеток, чтобы разработать конвейер для распознавания лиц, который напоминает методы распознавания лиц на основе деталей ". Наиболее распространенные подходы к распознаванию лиц основаны на CNNs, классе искусственных нейронных сетей (CNNS), которые могут автономно учиться находить закономерности в изображениях, например, идентифицируя конкретные объекты или людей. В то время как некоторые из этих методов достигли очень хороших результатов, недавняя работа высветила потенциал другого класса алгоритмов распознавания лиц, известных как преобразователи зрения (ViTs). В отличие от CNNs, которые обычно анализируют изображения целиком, ViTs разбивает изображение на участки определенного размера, а затем добавляет вложения к этим участкам. Результирующая последовательность векторов затем подается в стандартный преобразователь, модель глубокого обучения, которая по-разному взвешивает различные части анализируемых данных. "ViT, в отличие от CNNs, на самом деле может работать с участками, извлеченными из нерегулярных сеток, и не требует равномерно распределенной сетки выборки, используемой для свертки", - пояснили исследователи в своей статье. "Поскольку человеческое лицо представляет собой структурированный объект, состоящий из частей (например, глаз, носа, губ), и вдохновленный плодотворной работой по распознаванию лиц на основе деталей до глубокого обучения, мы предлагаем применить ViT к участкам, представляющим части лица". Архитектура vision transformer, созданная Sun и Цимиропулосом, получившая название part fViT, состоит из облегченной сети и vision transformer. Сеть предсказывает координаты лицевых ориентиров (например, носа, рта и т.д.), в то время как преобразователь анализирует участки, содержащие предсказанные ориентиры. Исследователи обучили различных трансформаторов лиц, используя два хорошо известных набора данных, а именно MS1MV3, который содержит изображения 93 431 человека, и VGGFace2, содержащий 3,1 миллиона изображений и 8600 идентификационных данных. Впоследствии они провели серию тестов для оценки своих моделей, а также изменили некоторые их функции, чтобы проверить, как это повлияло на их производительность. Их архитектура достигла замечательной точности для всех наборов данных, на которых она тестировалась, сравнимой со многими другими современными моделями распознавания лиц. Кроме того, их модели, по-видимому, успешно очерчивали лицевые ориентиры, не будучи специально обученными для этого. В будущем это недавнее исследование может вдохновить на разработку других моделей распознавания лиц, основанных на преобразователях зрения. Кроме того, архитектура исследователей могла бы быть реализована в приложениях или программных инструментах, которые могли бы извлечь выгоду из выборочного анализа различных ориентиров лица. | |
| Просмотров: 325 | |